

Why do we all love Python? For starters, it’s a beautiful and easy-to-learn programming language. Another reason: it comes with batteries included, meaning Python has many excellent libraries included by default. But in my opinion, it’s the 230,000 user-contributed packages that make Python really powerful and popular.
In this article, I handpicked the 15 best Python packages that I found most useful during my 10-year career as a Pythonista. Let’s go!
1. Dash
Dash is relatively new. It’s ideal for building data visualization apps in pure Python, so it’s particularly suited for anyone who works with data. Dash is a blend of Flask, Plotly.js, and React.js.
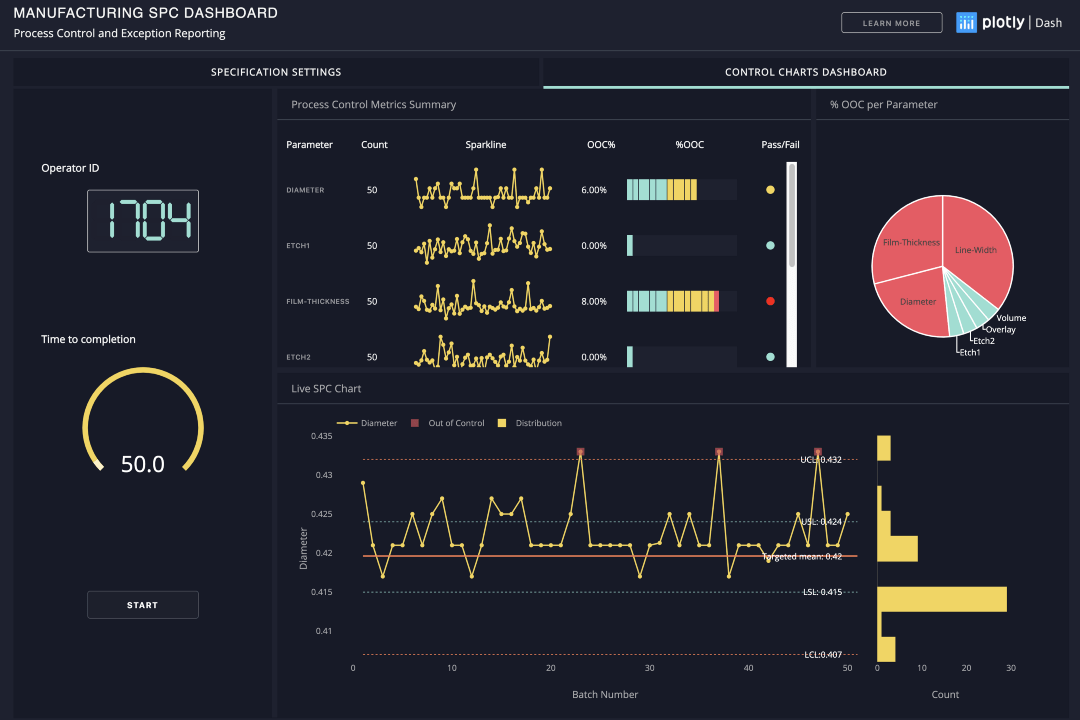
Dash allows you to quickly scaffold the stuff you need into a beautiful dashboard without the need to touch a single line of Javascript.
2. PyGame
Pygame is a Python wrapper module for the SDL multimedia library. Simple DirectMedia Layer is a cross-platform development library designed to provide low-level access to:
- audio
- keyboard
- mouse
- joystick
- graphics hardware via OpenGL and Direct3D
Pygame is highly portable and runs on nearly every platform and operating system. Although its a full-fledged game engine, you can also use this library to simply play an MP3 file right from your Python scripts.
PyGame has its own website, pygame.org, which includes tutorials and installation instructions.
3. Pillow
Pillow is a fork of the Python Image Library. You can use the library to create thumbnails, convert between file formats, rotate, apply filters, display images, and more. It’s ideal if you need to perform batch operations on many images.
To get a quick feel for it, this is how you can display an image from your Python code:
from PIL import Image
im = Image.open("kittens.jpg")
im.show()
print(im.format, im.size, im.mode)
# JPEG (1920, 1357) RGB
Or you can do it right from the Python shell (REPL) or IPython:
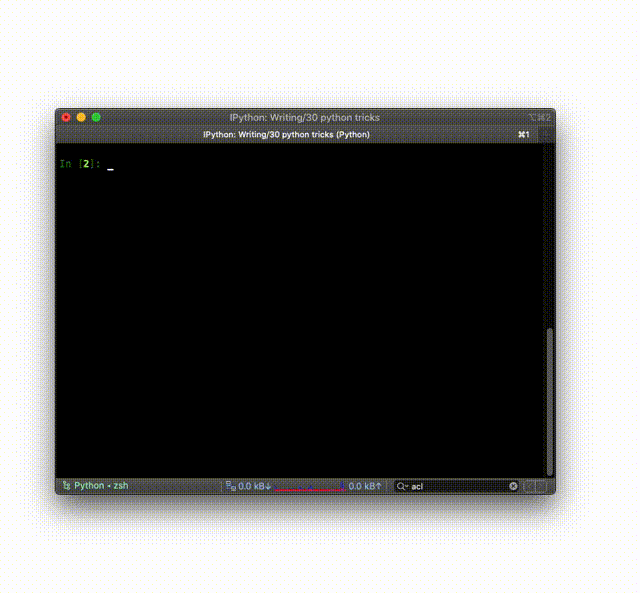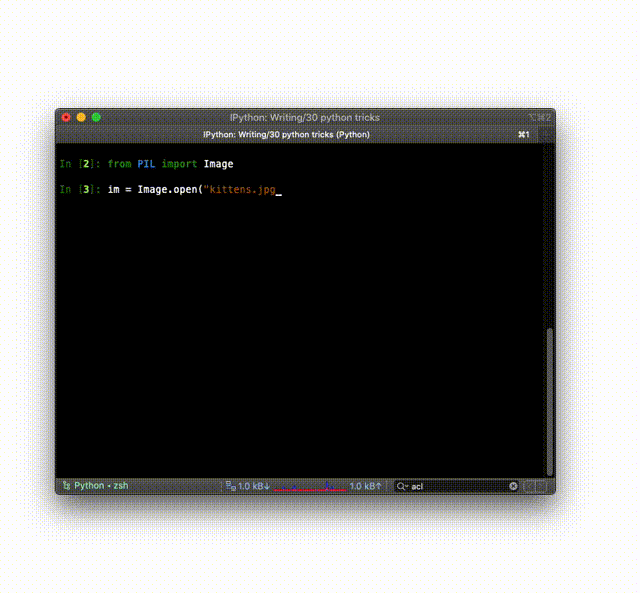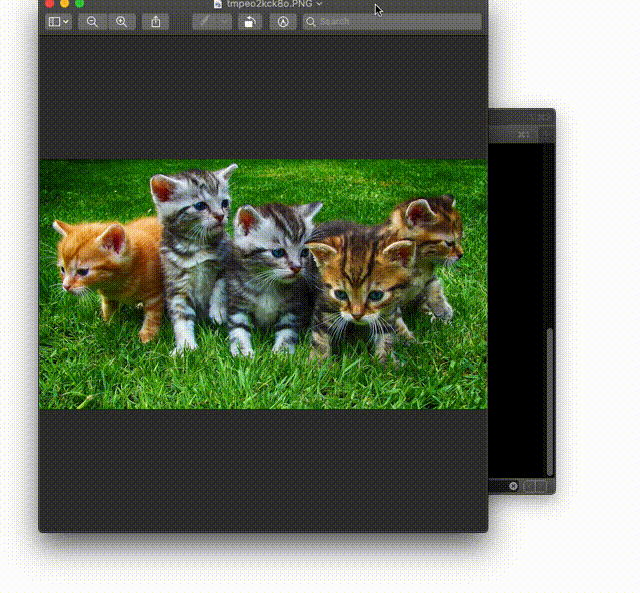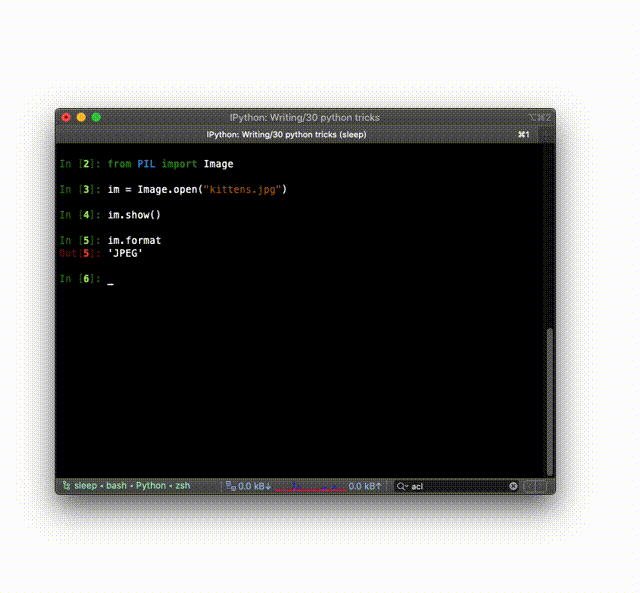
See the documentation for all the features.
4. Colorama
With Colorama, you can add some color to your terminal:
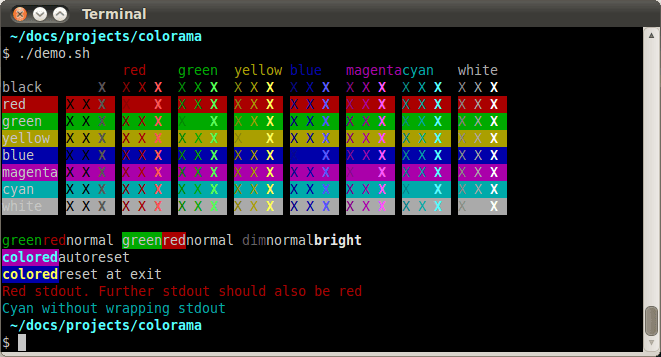
To get a feel for how easy this is, here’s some example code:
from colorama import Fore, Back, Style
print(Fore.RED + 'some red text')
print(Back.GREEN + 'and with a green background')
print(Style.DIM + 'and in dim text')
print(Style.RESET_ALL)
print('back to normal now')
It’s great for pimping up your Python scripts. The documentation is short and sweet and can be found right on the Colorama PyPI page.
In case you want this to work on Windows too, you’ll need to call colorama.init() before anything else.
5. JmesPath
Using JSON in Python is super easy since JSON maps so well on a Python dictionary. Additionally, Python comes with its own excellent json library to parse and create JSON. For me, it’s one of its best features. If I need to work with JSON, I turn to Python in a reflex.

But there’s something you might not realize you’re missing. If you just use json.loads() and get data from the dictionary manually, perhaps with a for-loop here and there, you’re in for a surprise.
JMESPath, pronounced “James path”, makes JSON in Python even easier. It allows you to declaratively specify how to extract elements from a JSON document. Here are some basic examples to give you a feeling for what it can do:
import jmespath
# Get a specific element
d = {"foo": {"bar": "baz"}}
print(jmespath.search('foo.bar', d))
# baz
# Using a wildcard to get all names
d = {"foo": {"bar": [{"name": "one"}, {"name": "two"}]}}
print(jmespath.search('foo.bar[*].name', d))
# [“one”, “two”]
This is just touching the surface of all its possibilities. See the documentation and the PyPI page for more.
6. Requests
Requests is building on the most downloaded Python library in the world, urllib3. It makes web requests really simple, yet remains very powerful and versatile. Chances are you know this one by heart already, but I couldn’t make this list without mentioning it! It’s the best Python package when it comes to HTTP.
Just to show how easy requests can be:
import requests
r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
r.status_code
# 200
r.headers['content-type']
# 'application/json; charset=utf8'
r.encoding
# 'utf-8'
r.text
# u'{"type":"User"...'
r.json()
# {u'disk_usage': 368627, u'private_gists': 484, ...}
That is a very basic example, but requests can also do all the advanced stuff you can think of, like:
- Authentication
- Using cookies
- Performing POSTs, PUTs, DELETEs, etc.
- Using custom certificates
- Working with sessions
- Working with proxies
- … and so much more!
Links:
7. Simplejson
What’s wrong with the native json module in Python? Nothing! In fact, Python’sjson is simplejson. Meaning, Python takes a version of simplejson and incorporates it into each release. But usingsimplejson has some advantages:
- It works on more Python versions.
- It is updated more frequently than the version shipped with Python.
- It has (optional) parts that are written in C, making it very fast.
Due to these facts, something you will often see in scripts that work with JSON is this:
try: import simplejson as json except ImportError: import json
I would just use the defaultjson, unless you specifically need:
- raw speed
- something that is not in the standard library
Simplejson can be a lot faster than json, because it has some critical parts implemented in C. This speed will not be of interest to you, unless you are working with millions of JSON files. In that case, also check out UltraJSON, which is supposed to be even faster because almost all of it is written in C.
8. Emoji
This one will either impress or repulse, depending on who’s looking. On a more serious note, this one came in handy when I was analyzing social media data.

First, install the emoji module with pip install:
pip3 install emoji
With this installed, you can import and use the module as follows:
import emoji
result = emoji.emojize('Python is :thumbs_up:')
print(result)
# 'Python is ????'
# You can also reverse this:
result = emoji.demojize('Python is 👍')
print(result)
# 'Python is :thumbs_up:'
Visit the emoji package page for more examples and documentation.
9. Chardet
You can use the chardet module to detect the charset of a file or data stream. This is useful when analyzing big piles of random text, for example. But it can also be used when working with remotely downloaded data where you don’t know what the charset is.
After installing chardet, you also have an extra command-line tool called chardetect, which can be used like this:
$ chardetect somefile.txt somefile.txt: ascii with confidence 1.0
Of course, you can also use the library programmatically, check out the docs.
10. Python-dateutil
The python-dateutil module provides powerful extensions to the standard datetime module. It’s my experience that where regular Python datetime functionality ends, python-dateutil comes in.
You can do so much cool stuff with this library. I’ll limit the examples to just one that I found particularly useful: fuzzy parsing of dates from log files and such:
from dateutil.parser import parse logline = 'INFO 2020-01-01T00:00:01 Happy new year, human.' timestamp = parse(logline, fuzzy=True) print(timestamp) # 2020-01-01 00:00:01
See the full documentation for more features, like:
- Computing of relative deltas (next month, next year, next Monday, last week of the month, etc) and relative deltas between two given date objects.
- Computing of dates based on recurrence rules, using a superset of the iCalendar specification.
- Timezone (tzinfo) implementations for tzfile files (/etc/localtime, /usr/share/zoneinfo, etc), TZ environment string (in all known formats), iCalendar format files, given ranges (with help from relative deltas), local machine timezone, fixed offset timezone, UTC timezone, and Windows registry-based time zones.
- Internal up-to-date world timezone information based on Olson’s database.
- Computing of Easter Sunday dates for any given year, using Western, Orthodox, or Julian algorithms.
11. Progress bars: progress and tqdm
I’m cheating a little here since these are two packages. But it doesn’t feel fair to leave one of them unmentioned.
You can create your own progress bar, which is fun to do perhaps, but it’s quicker and less error-prone to use the progress or tqdm package.
Progress
With this one, you can create a progress bar with minimal effort:
from progress.bar import Bar
bar = Bar('Processing', max=20)
for i in range(20):
# Do some work
bar.next()
bar.finish()
The following animation demonstrates all the available progress types:

The short but concise documentation can be found right on the progress PyPI page.
tqdm
tqdm does roughly the same but seems to be a little more up-to-date. First a little demonstration in animated gif form:
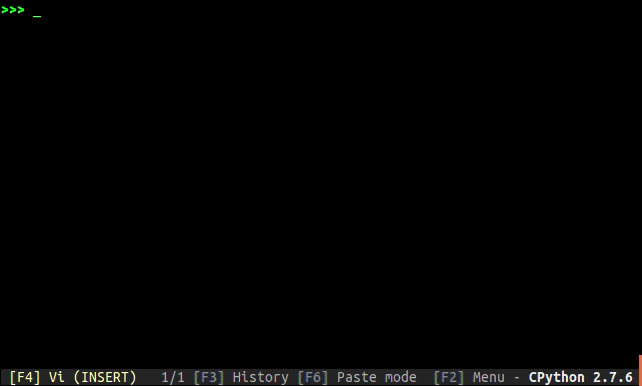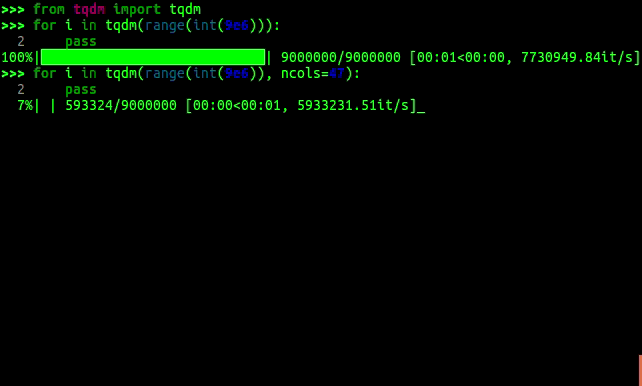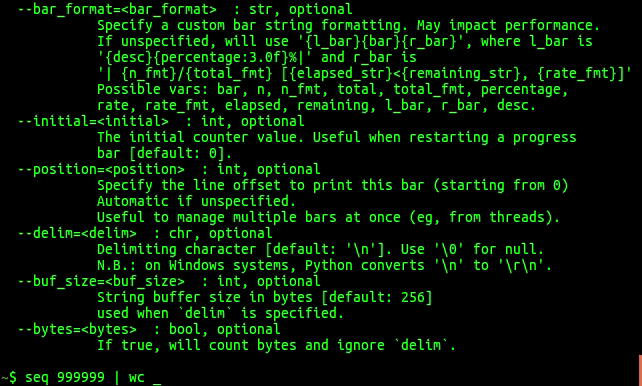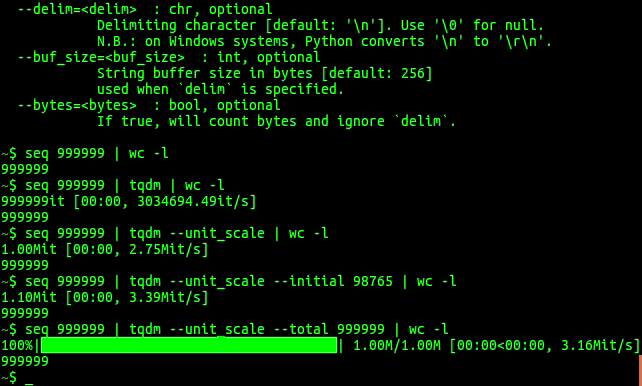
tqdm has an extra trick up its sleeve compared to progress: it can be used on the command line like this:
$ tar -zcf - docs/ | tqdm --bytes --total `du -sb docs/ | cut -f1` > backup.tgz 32%|██████████▍ | 8.89G/27.9G [00:42<01:31, 223MB/s]
More examples and documentation can be found on the tdqm Github page.
12. IPython
I’m sure you are aware of the Python interactive shell. It’s a great way to tinker with Python. But do you know the IPython shell as well? If you use the interactive shell a lot and you don’t know IPython, you should really check this one out!
Some of the features the enhanced IPython shell offers are:
- Comprehensive object introspection.
- Input history, persistent across sessions.
- Caching of output results during a session with automatically generated references.
- Tab completion, with support for completion of python variables and keywords, filenames, and Python functions.
- ‘Magic’ commands for controlling the environment and performing many tasks related either to IPython or the operating system.
- Session logging and reloading.
- Integrated access to the pdb debugger and the Python profiler.
- A less known feature of IPython: its architecture also allows for parallel and distributed computing.
If you’re interested, you can get some quick getting started hints to IPython usage from my article on it. IPython is the core for Jupyter notebook, which is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text.
13. Homeassistant
I love home automation. It’s a bit of a hobby for me, but also something I’m dead serious about since by now it’s controlling large parts of our house. I tied together all systems in our house by using Home Assistant. Although it’s really a complete application, you can install it as a Python PyPI package too.
- Most of our lamps are automated and our blind as well.
- I monitor our gas usage and power usage and production (solar panels).
- I can track the location of most of our phones, and start actions when then enter a zone, like switching on the garage lights when I come home.
- It can also control all our entertainment systems, like our Samsung TV and Sonos speakers.
- It’s able to auto-discover most devices on your network, so it’s really easy to get started.
I’ve been using Home Assistant daily for 3 years now, and it’s still in beta, but it’s by far the best platform of all the ones I tried. It’s able to integrate and control all kinds of devices and protocols, and it’s all free and open source.
If you’re interested in automating your home, make sure to give it a chance! If you want to learn more, visit their official site. If you can, install it on a Raspberry Pi. It’s by far the easiest and safest way to get started. I installed it on a more powerful server, inside a Docker container running Python.
14. Flask

Flask is my go-to library for creating a quick web service or a simple website. It’s a microframework, which means Flask aims to keep the core simple but extensible. There are more than 700 extensions, both official and from the community.
If you know you’ll be developing a huge web app, you might want to look into a more complete framework instead. The most popular in that category is Django.
15. Beautiful soup
If you’ve pulled some HTML from a website, you need to parse it to get what you actually need. Beautiful Soup is a Python library for pulling data out of HTML and XML files. It provides simple methods for navigating, searching, and modifying a parse tree. It is very powerful and is able to handle all kinds of HTML, even if it’s broken. And believe me, HTML is often broken, so this is a very powerful feature.
Some of its main features:
- Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8. You don’t have to think about encodings.
- Beautiful Soup sits on top of popular Python parsers like
lxmlandhtml5lib, allowing you to try out different parsing strategies or trade speed for flexibility. - Beautiful Soup parses anything you give it and does the tree traversal stuff for you. You can tell it “Find all the links”, or “Find the table heading that’s got bold text, then give me that text.”
Conclusion
There you have it: the best Python packages I could think of. Is there something missing in this list? Feel free to leave a comment!



This post was on Reddit, and there people asked why the Rich package is not on the list. I tried it and it’s awesome, so check it out!
Rich is a Python library for rich text and beautiful formatting in the terminal. The Rich API makes it easy to add color and style to terminal output. Rich can also render pretty tables, progress bars, markdown, syntax highlighted source code, tracebacks, and more.