

A Bloom filter in Python efficiently tests if an element is a member of a set. It was first proposed by Burton Howard Bloom all the way back in 1970. Although a little unknown, they have become ubiquitous, especially in distributed systems and databases. Bloom filters are an excellent time and memory saver.
After reading this article, you’ll know:
- What Bloom filters are
- Why and when you can use a Bloom filter
- How to create and use a Bloom filter in Python
I’ll illustrate with practical Python-based example code. The examples will be so easy to understand that non-Python programmers should have no problem following them.
Table of Contents
Bloom filter in Python
We’ll dive right in with a little demonstration before explaining exactly what a bloom filter is and does. It will make the explanation that follows a lot easier to grasp!
PyPI, the Python Package Index, contains an easy-to-use package, aptly called bloom-filter. Install it with the pip install command and you should be good to go:
pip3 install bloom-filter
In the Python REPL, we can use this package interactively:
>>> from bloom_filter import BloomFilter
>>> b = BloomFilter(max_elements=1000, error_rate=0.1)
>>> b.add('hello')
>>> b.add('world')
>>> 'hello' in b
True
>>> 'world' in b
True
>>> 'eric' in b
False
>>> _
The good news is that you don’t need a computer science degree to understand the takeaway concept: test if an element is a member of a set.
In fact, the simple demonstration above pretty much shows it all. However, to know when and where to apply a bloom filter, and what settings are sensible, you’ve got to dive in a little deeper than this.
What does a bloom filter offer us?
Bloom filters test if an element is part of a set. In our example above, our set contains two strings, ‘hello’ and ‘world.’ It correctly tells us that these words are part of the set, and other words aren’t.
You could have used a Python list, a Python set, or a tuple and test membership that way, right? Correct! But what if you have a large number of words in your set? Like tens of thousands, or a million?
I’m not sure how Python would handle such amounts. It could probably do it, to some extent, but at what cost? I can tell you exactly: at the cost of memory. Storing millions of words will eat up memory as fast as the cookie monster gobbles away his cookies.
And this is exactly the problem bloom filters solve. They do their work without needing to store all the elements of a set. However, there’s always a trade-off, and the tradeoff here is accuracy.
Bloom filters test if an element is part of a set, without needing to store the entire set
When to use a bloom filter?
We need to learn more about this accuracy trade-off before properly deciding if bloom filters are useful for your use case.
An important property of a Bloom filter is that it never returns a false negative, but it can return false positives. If these terms are unclear to you:
- A false negative: the filter says the element is not part of the set, while in fact, it is. This won’t happen because of how Bloom filters work internally.
- A false positive: the filter says the element is part of the set, while in reality, it is not. This can happen, and you should account for it in your code/algorithms.
In even simpler words, a query on a Bloom filter can return a “this element is possibly in the set” or a “this element is definitely not in the set.”
The fact that they can return false positives is the accuracy trade-off I was talking about. If you can live with less than 100% accuracy, bloom filters are a great way to save time and memory.
The sieve analogy
You can compare Bloom filters with a sieve, specially formed only to let through certain elements:
- The known elements will fit the holes in the sieve and fall through.
- Even though they’ve never been seen, some elements will also fit the holes in the sieve and fall through. These are our false positives.
- Other elements, never seen before, won’t fall through: the negatives.

Controlling accuracy with memory
The more memory you give a bloom filter, the more accurate it will become. Why’s that? Simple: the more memory it has to store data in, the more information it can store, and the more accurate it can be.
But, of course, we use a Bloom filter to save memory, so you need to find a balance between memory usage and the number of acceptable false positives.
Given these facts, you may already get a feeling for when to use a Bloom filter. In general terms, you use them to reduce the load on a system by reducing expense lookups in some data tables at a moderate memory expense. This data table can be anything. Some examples:
- A database
- A filesystem
- Some kind of key-value storage
An example use-case
Let’s look at an example use case to better understand how Bloom filters in Python can help.
Imagine a large, multi-machine, networked database. Each lookup for a record in that distributed database requires, at its worst, querying multiple machines at once. On each machine, a lookup means accessing large data structures stored on a disk. As you know, disk access, together with networking, is one of the slowest operations in computer science.
Now imagine that each machine uses a bloom filter, trained with the records stored on disk. Before accessing any data structure on disks, the machine first checks the filter. If it gives a negative, we can be certain that this machine does not store that record, and we can return this result without accessing disks at all.
If a bloom filter can prevent 80% of these disk lookups, in exchange for some extra memory usage, that may be well worth it! Even if the filter would save us only 30% of disk lookups, that may still be an enormous increase in speed and efficiency.
Choosing the trade-off
We do need to find an optimum between saving memory and saving time and CPU cycles.
In our example code, we initialize a Python Bloom filter by giving a number of elements and an error rate:
b = BloomFilter(max_elements=1000, error_rate=0.1)
We’re basically saying: we expect to store a maximum of 1000 elements, and we can accept a 0.1 error rate, which means that 10% of the lookups might give a false positive. The library will calculate the proper size for us now.
How do bloom filters work?
By now, you know enough to use bloom filters without even knowing how they work internally. This section will touch on the basics and leave you with some links to dive in deeper if you want.
A Bloom filter is an array of bits, all set to 0 initially. The more bits there are, the more the filter can store. If you add an element, this element is hashed with multiple hash functions. The hashing result determines which bits in the filter are set to 1. If a bit was already set to one, it’s left like that.
We can now look at two extremes: an empty filter, and a completely saturated one.
Empty Bloom filter
If the filter is empty, all array bits are zero. imagine a new element w, which we haven’t seen before and was not added to the Bloom filter before. When we ask if w is in the filter, the following happens:
- The element w is hashed
- The result is checked against the positions in the filter
- Everything is set to zero, so the Bloom filter returns a negative: w not in the set.
A saturated Bloom filter
The more elements you add to the filter, the more bits are set to one. Until, eventually, all bits are 1. If we check our unknown element w again, this happens:
- The element w is hashed
- The result is checked against the positions in the filter
- Because all positions are 1, the filter returns a positive: w is part of the set according to this Bloom filter
And the filter will keep returning false positives, whatever you feed it.
A well-functioning Bloom filter
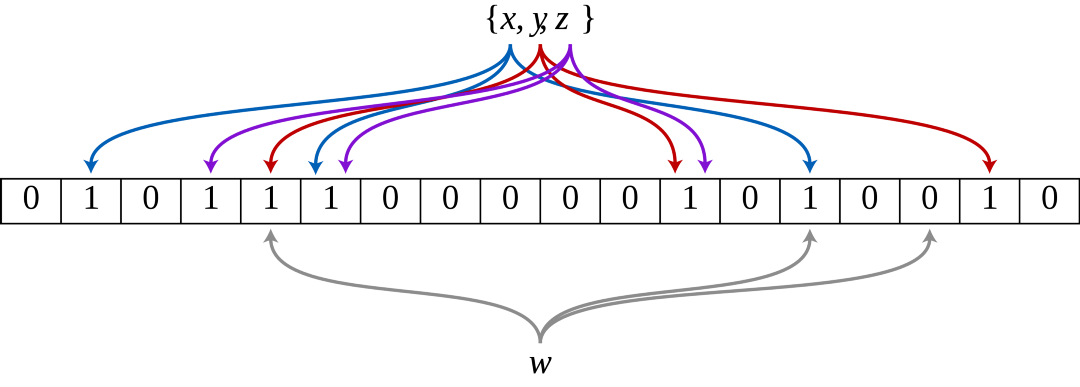
If we add a proper amount of elements, say x, y, and z, the filter will function optimally. In the image below, our hashed elements will set some of the positions in our filter to 1. If we check our unknown element w against the filter, some of the positions will be 1, but one of them is 0. That’s why the filter can assure us this element is not part of the set.
How much will a Bloom filter save me?
There’s no simple answer to this question. Your best bet is to test your code with and without them extensively. Sometimes Bloom filters can be an enormous help, but there are also cases in which they are not that efficient. See the last link below, for example.
Keep learning
Here are some resources that help you to learn more about Bloom filters and how they are used. I also included the original paper by Bloom himself and an article on the Cloudflare blog that shows when Bloom filters are not the best choice:
- Wikipedia’s Bloom filter article
- Space/Time Trade-offs in Hash Coding with Allowable Errors, Burton Howard Bloom, 1970.
- Theory and Practice of Bloom Filters for Distributed Systems, Sasu Tarkoma, Christian Esteve Rothenberg, and Eemil Lagerspetz, 2011
- When Bloom filters don’t Bloom, Marek Majkowski (Cloudflare), 2020.


